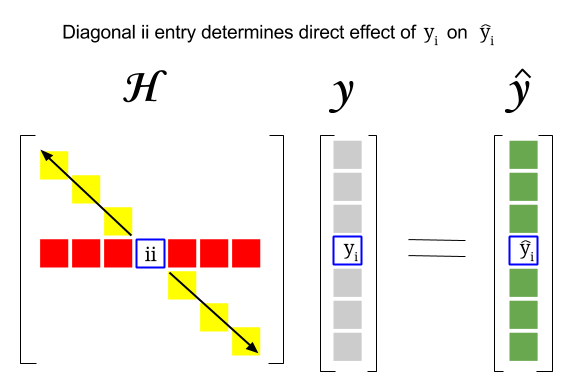
Hat Matrix Diagonal
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Introduction To The Hat Matrix In Regression Youtube

Hat Matrix An Overview Sciencedirect Topics
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Matrix Hat A Knit Pattern For When You Need To Escape Knitted Hats Hat Knitting Patterns Knitting

We givenecessary and sufficient conditions on the space of design matrix under which thecorresponding Hat matrix elements get desired extreme values.
Hat matrix diagonal. The hat matrix projection matrix P in econometrics is symmetric idempotent and positive definite. H XXX 1X Where hii are the diagonal elements of the hat matrix the HC2 variance estimator is VˆβHC2 XX 1Xdiag e2 i 1 hiiXXX 1. Calculating the diagonal-entries of Q only or else we would have a result matrix of NN 25e8 entries for your numbers i used this.
Then 6 3k - Ok JV 1Jp Jlk Vkk1k2I - k where rk Yk - fk. Note that Jp VJ1J is the expected Fisher information matrix at. So hii pii cii pii 1 n.
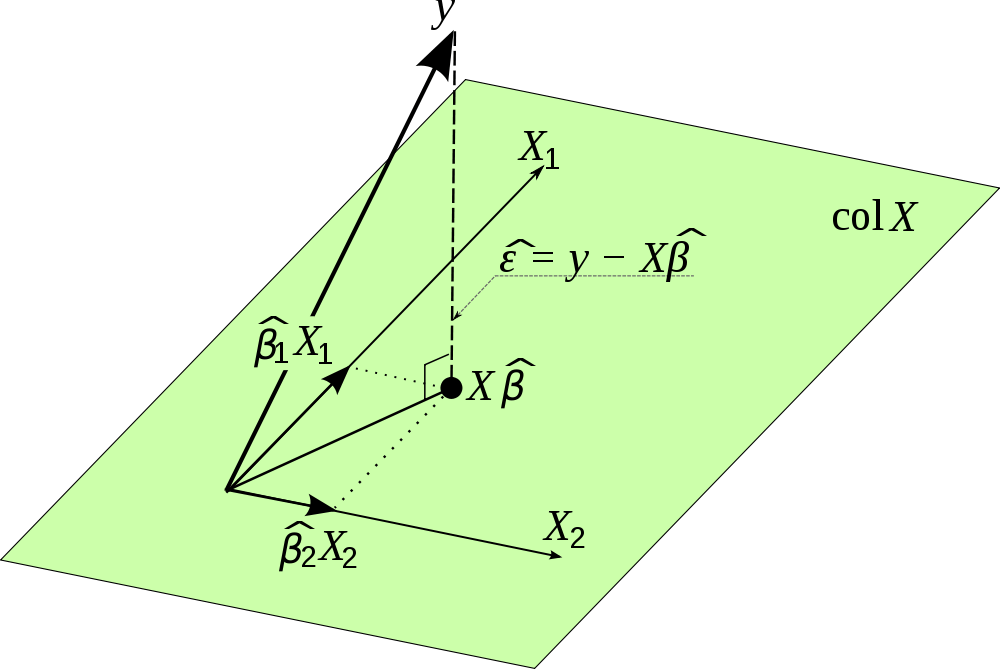
This matrix is shown to have many of the same properties and is seen to play the same role in the variances and covariances. Theconfidence interval estimate of the mean response. The matrix which transforms the data vector to the vector of fitted values for smoothing splines is termed the hat matrix.
The elements of the hat matrix may provide fur- ther information which is complementary to that re- suiting from the residuals. The hat matrix diagonal element for observation i denoted hi reflects the possible influ-ence of X. Any observation having a large hi is called a leverage point.
X-space is the data points associated diagonal element hiin the hat matrix. We did not call it hatvalues as R contains a built-in function with such a name. H i i 1 n x i x 2 x j x 2 where j 1 n.
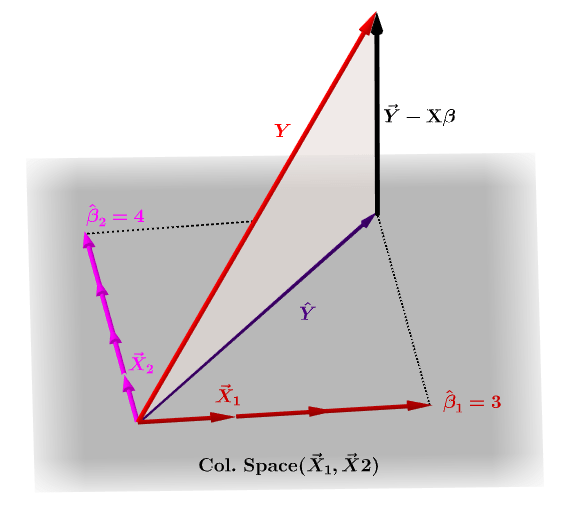
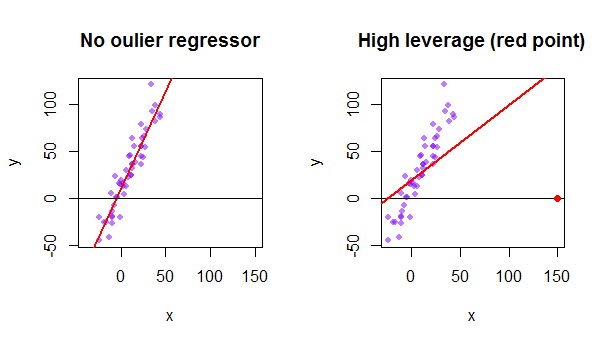
So P is also a projection matrix. Data points that are far from the centroid of the X-space are potentially influentialA measure of the distance between a data point x i and the centroid of the X-space is the data points associated diagonal element h i in the hat matrix. The standard hat matrix is written.
What Is The Importance Of Hat Matrix H X X Top X 1 X Top In Linear Regression Cross Validated

Hat Matrix An Overview Sciencedirect Topics

Hat Matrix Freakonometrics

Properties Of Leverage Points In Regression With Proofs Note Typo Youtube

How To Calculate Hat Matrix For Penalized Spline Regressions Cross Validated

Cyber Security Blue Team Shield And Matrix Rain Black Bg Sticker By Fast Designs Team Blue Cyber Security Cyber

Threat Intelligence Cyber Security Sticker Happy Sabbath Quotes Cyber Sabbath Quotes

A Message Delivered Ader Adererror Message Spring Summer 2018 Resort Collection Lookbook Web Mobile World Cap Photo Editing Digital Content Ader

Hat Matrix An Overview Sciencedirect Topics

On Leverage R Bloggers

3 20 Points Let H X X X 1x Ernxn Be The Hat Chegg Com

Cyber Security Badge Seal Red Transparent Sticker Sticker By Fast Designs Transparent Stickers Coloring Stickers Cyber Security

Fleur De Lis Black Gold Dotted Diagonal Pattern Phone Case Pattern Phone Case Pattern Iphone Case Iphone Case Covers

