Hat Matrix Diagonal Elements
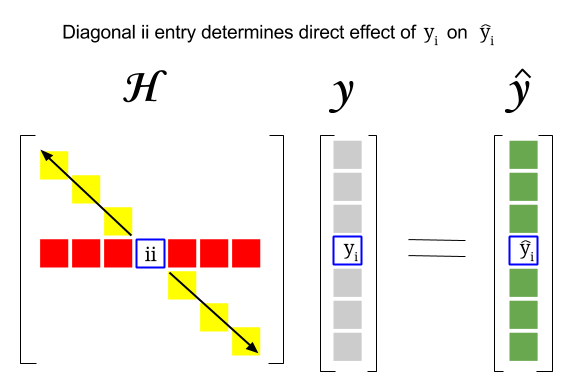
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Hat Matrix An Overview Sciencedirect Topics
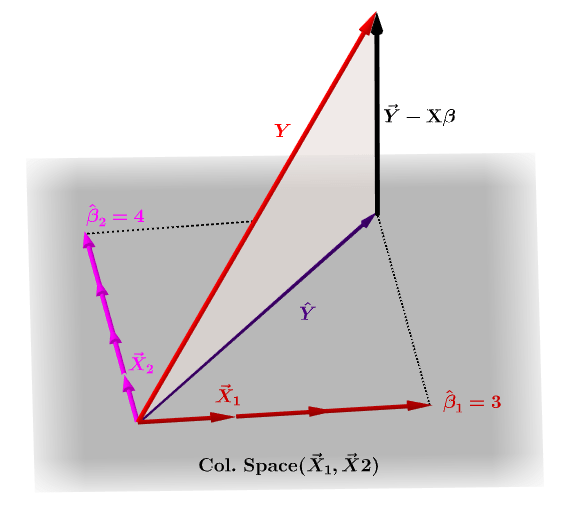
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Introduction To The Hat Matrix In Regression Youtube

Hat Matrix Freakonometrics
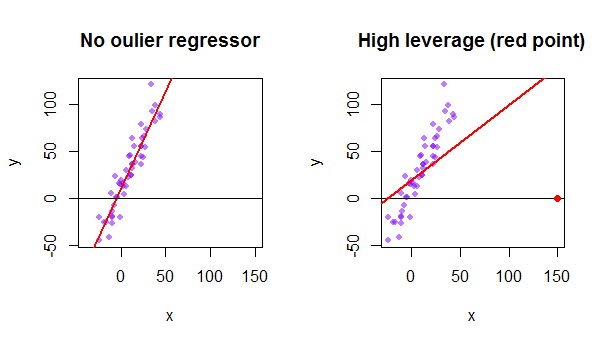
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

That is the predictor values are far from the mean vector using Mahalanobis distance.
Hat matrix diagonal elements. The diagonal elements of H hii are called leverages and satisfy where p is the number of coefficients and n is the number of observations rows of X in the regression model. This implies that the correlations are zero. Hat matrix is a special case with A XX.
Ones in the diagonal elements specify that the variance of eachi is 1 times2. 0 h i i 1. We givenecessary and sufficient conditions on the space of design matrix under which thecorresponding Hat matrix elements get desired extreme values.
Along the way I present the proo. Leverages are obtained from the hat matrix H which is an n x n projection matrix. Principalcomponentanal-ysisseeksatransformation PX Y 2 such that the diagonal elements of C Y are rank-.
New and sharper lower bound for off-diagonal elements of the Hat matrix in theintercept model which is shorter than those for the no-intercept model. H XXX 1X Where hii are the diagonal elements of the hat matrix the HC2 variance estimator is VˆβHC2 XX 1Xdiag e2 i 1 hiiXXX 1. Where H XXT X 1XT is an n nmatrix which puts the hat on y and is therefore.
The leverage of the i th observation is the i th diagonal element hi of H. For a binary response logit model the hat matrix diagonal elements are If the estimated probability is extreme less than 01 and greater than 09 approximately then. The standard hat matrix is written.
This answer focus on the use of triangular factorization like Cholesky factorization and LU factorization and shows how to compute only diagonal elements. If hi is large the i th observation has unusual predictors X 1i X 2i X pi. Properties and Interpretation Week 5 Lecture 1 1 Hat Matrix 11 From Observed to Fitted Values The OLS estimator was found to be given by the p 1 vector b XT X 1XT y.

Diagonal Matrices Youtube

On Leverage R Bloggers

Hat Matrix An Overview Sciencedirect Topics

Properties Of Leverage Points In Regression With Proofs Note Typo Youtube

Cyber Security Blue Team Shield And Matrix Rain Black Bg Sticker By Fast Designs Team Blue Cyber Security Cyber

Introduction To The Hat Matrix In Regression Youtube

Hat Matrix An Overview Sciencedirect Topics

Threat Intelligence Cyber Security Sticker Happy Sabbath Quotes Cyber Sabbath Quotes

Defcon Owl Traps Kills Owls Dead Flat Bg Sticker By Fast Designs Vinyl Sticker Sticker Design Owl

Try Harder Black Bg Sticker By Fast Designs Try Harder Stickers Black Bg

Fleur De Lis Black Gold Dotted Diagonal Pattern Phone Case Pattern Phone Case Pattern Iphone Case Iphone Case Covers

Map Analysis Gis3015 Similarity Matrix Map Analysis Data Visualization Heat Map

Hat Matrix An Overview Sciencedirect Topics

