Hat Matrix In Ridge Regression

How To Calculate Hat Matrix For Penalized Spline Regressions Cross Validated
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
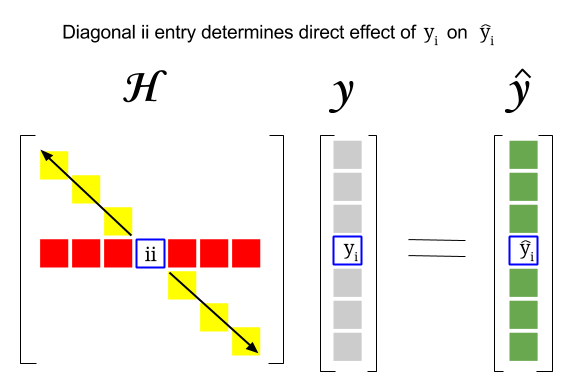
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
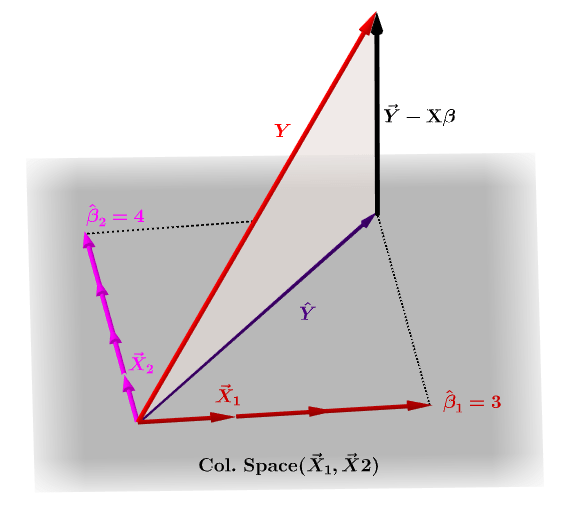
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
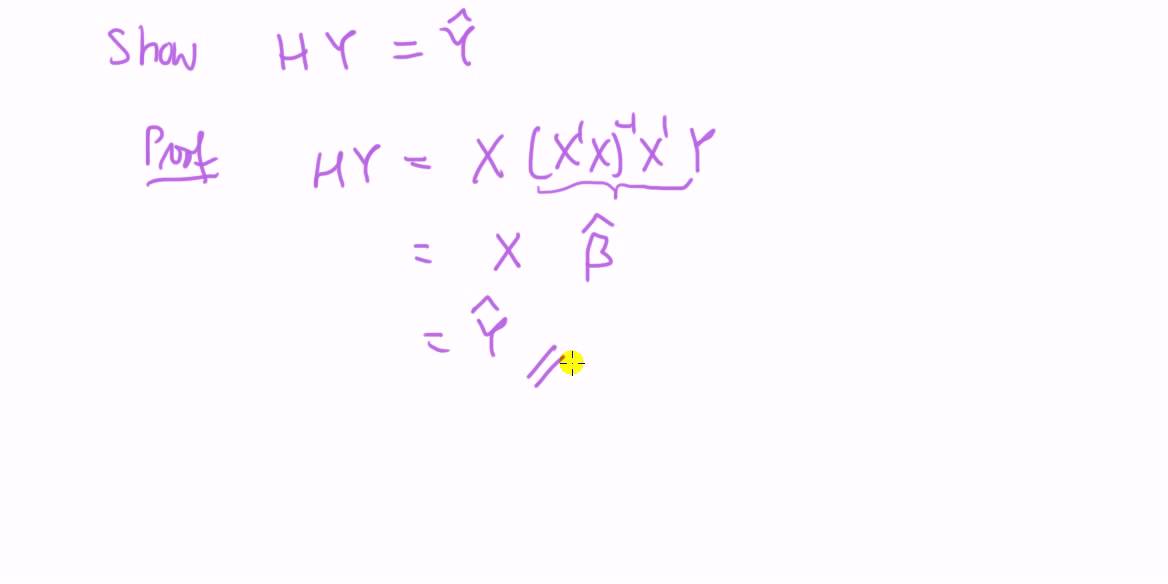
1When variables are highly correlated a large coe cient in one variable may be alleviated by a large coe cient in another variable which is negatively correlated.
Hat matrix in ridge regression. In ridge regression however the formula for the hat matrix should include the regularization penalty. Beginequation Y_i sum_j1p X_ijbeta_j epsilon_i endequation. The hat matrix can be computed using formula XXXkI-1X equivalently λ_jλ_jk.
1 Hat Matrix 11 From Observed to Fitted Values The OLS estimator was found to be given by the p 1 vector b XT X 1XT y. Model Selection Criteria Plots. Returns a list of matrix for each biasing parameter K.
Where H XXT X 1XT is an n nmatrix which puts the hat on y and is therefore referred to as the hat matrix. ISRM and m-scale Plot. Not presently used in this implementation.
Autumn Quarter 20062007 Regularization. The predicted values ybcan then be written as by X b XXT X 1XT y. The SVD and Ridge Regression Data augmentation approach The ℓ2 PRSS can be written as.
Model Selection Criteria for Ridge Regression. Some ridge regression software produce information criteria based on the OLS formula. Continuing this analogy the degrees of freedom of ridge regression is given by the trace of the hat matrix.
Therefore we create a bias matrix. β XX λIp1XY β X X λ I p 1 X Y. My understanding is that in ridge regression you add a penalty term which is equivalent to having a zero-centered normal prior on the parameters.

Using The Hat Matrix To Detect Influential Observations In Logistic Regression Cross Validated

Introduction To The Hat Matrix In Regression Youtube

5 1 Ridge Regression Stat 897d

Hat Matrix An Overview Sciencedirect Topics

Kernel Ridge Regression A Toy Example Business Forecasting

On Leverage R Bloggers
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
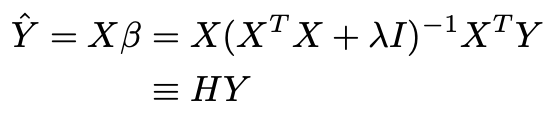
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science

Side 2019 3

Hat Matrix An Overview Sciencedirect Topics

4 1 Shrinkage Notes For Predictive Modeling
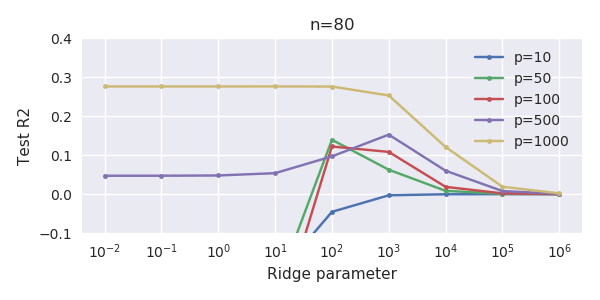
Is Ridge Regression Useless In High Dimensions N Ll P How Can Ols Fail To Overfit Cross Validated

