Hat Matrix Is Symmetric

1st 2 Parts Properties Of Hat Matrix Ie Symmetric Idempotent Youtube
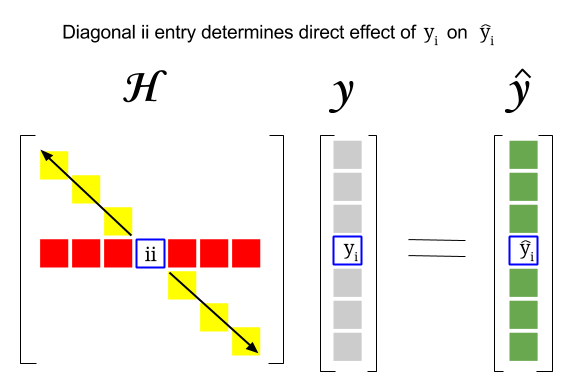
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
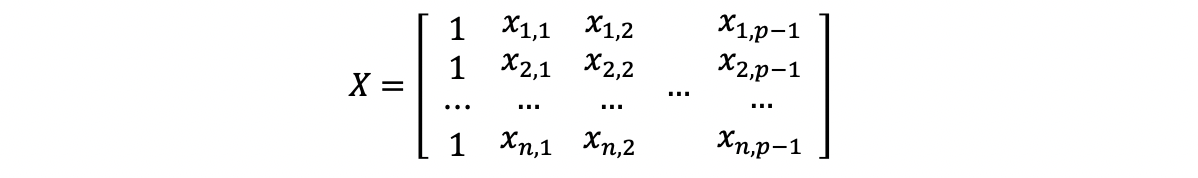
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

Hat Matrix An Overview Sciencedirect Topics
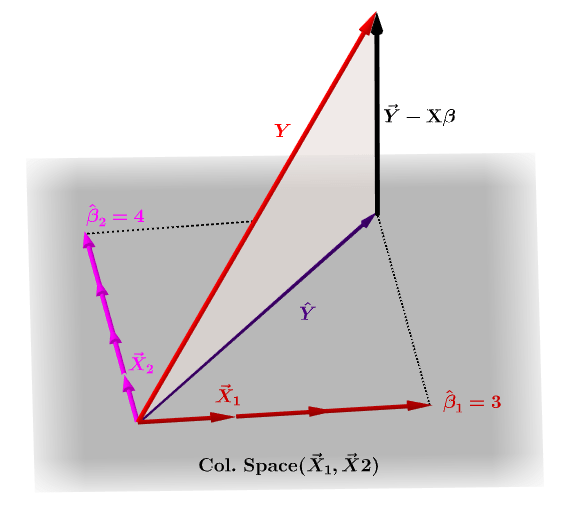
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
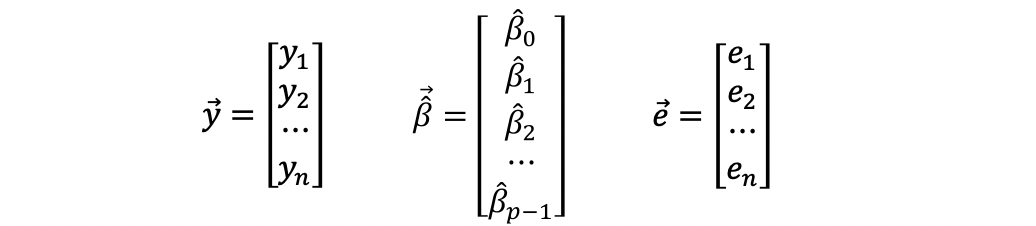
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

In hindsight it is geometrically obviousthat we should have hadH2H.
Hat matrix is symmetric. For anyy2Rnthe closest point toyinsideof MisHy. I 1 n is a data matrix of p explanatory variables and ϵ is a vector of errors. As a result we can concisely represent any skew symmetric 3x3 matrix as a 3x1 vector.
Also for the matrix for all the values of i and j. It follows thatthe hat matrixHis symmetric too. Square matrix issymmetric if it can be flippedaround its main diagonal that is xij xji.
In otherwords if Xis symmetric XX0. Where p is the number of coefficients and n is the number of observations rows of X in the regression model. R si r i p 1 H ii d si d i p 1 H ii Generally speaking the standardized deviance residuals tend to be preferable because they are more symmetric than the standardized Pearson residuals but both are commonly used.
The hat operator allows us to switch between these two representations. If the transpose of a matrix is equal to the negative of itself the matrix is said to be skew symmetric. Let A be a symmetric and idempotent n n matrix.
A symmetric idempotent matrix such asHis called a. A matrix can be skew symmetric only if it is square. Let hij indicate the ij-th element of H.
The hat matrix is symmetric The hat matrix is idempotent ie. Symmetric Because the hat matrix is a specific kind of projection matrix then it. HH I-HI-HH2H I-H2I-H2.

Nyx Sock Knitting Patterns Knitting Socks Knitting Designs
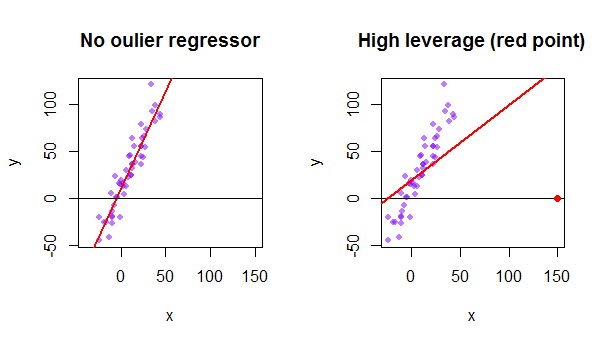
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
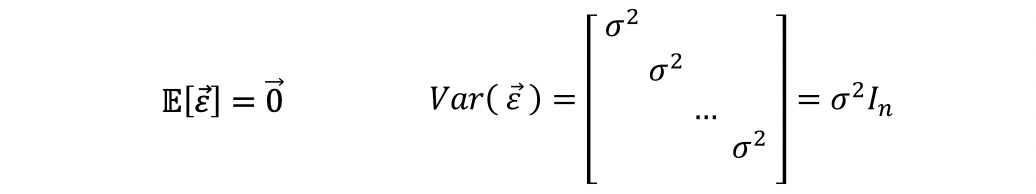
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

Introduction To The Hat Matrix In Regression Youtube
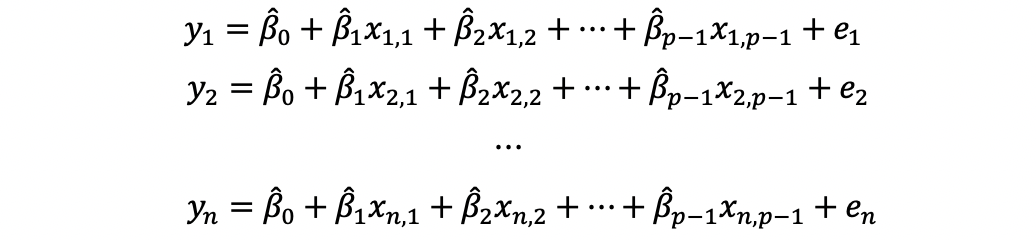
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

Exercise 4 2 Class 12 Introduction Maths Solutions Exercise Class

Hat Matrix An Overview Sciencedirect Topics

Pin On Squash Gifts

Radial Symmetry Gimp Radial Symmetry Geometric Shapes Gimp Tutorial

Differential Equations Lecture 4 1 Preliminary Theory Linear Equations Linear Equations Differential Equations Equations

How To Derive Variance Covariance Matrix Of Coefficients In Linear Regression Cross Validated

Hat Matrix An Overview Sciencedirect Topics

Red Chair Morpheus Is Sitting On In The Matrix And Ninja Turtle Shell Red Chair Chair Home Decor

