Hat Matrix Trace

Proof That The Trace Of Mx Is P Youtube

Hat Matrix Freakonometrics

Introduction To The Hat Matrix In Regression Youtube
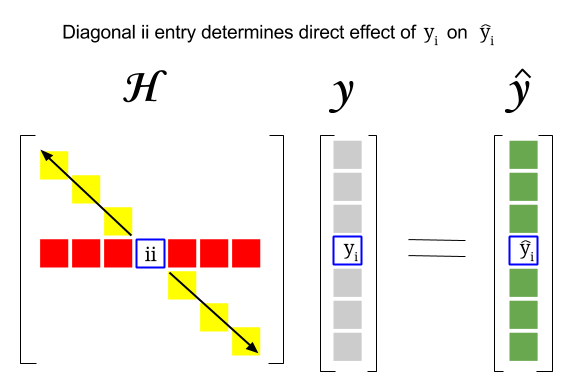
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Projection Matrix Help Cross Validated

Get Hat Matrix From Qr Decomposition For Weighted Least Square Regression Stack Overflow

In any other case and eg.
Hat matrix trace. The number of parameters decreases as smoothing increases. The first diagonal block is the hat matrix for ridge regression which is not a projector anymore it has eigenvalues less than one The full matrix is the hat matrix for OLS in the augmented data representation for ridge so its trace is the dimension of the column space of leftbeginsmallmatrix X sqrtlambda I endsmallmatrix. The hat matrix is also known as the projection matrix because it projects the vector of observations y onto the vector of predictions thus putting the hat on y.
Value of the loglikelihood function evalued at params. Its usually called the hat matrix for obvious reasons or if we want to sound more respectable the in uence matrix. Proof that trace of hat matrix in linear regression is rank of X.
Ridge regression degrees of freedom. Trace of a product The next proposition concerns the trace of a product of matrices. H X XTX 1XT and determines the fitted or predicted values since.
In uence Since His not a function of y we can easily verify that mb iy j H ij. The trace of an idempotent matrix the sum of the elements on its main diagonal equals the rank of the matrix and thus is always an integer. The matrix H plays an important role in the linear regression analysis.
The hat matrix projection matrix P in econometrics is symmetric idempotent and positive definite. The trace of the hat matrix is a standard metric for calculating degrees of freedom. Let hij indicate the ij-th element of H.
The hat matrix H is defined in terms of the data matrix X. It describes the influence each response value has on each fitted value. For S idempotent S0S S these are the same.
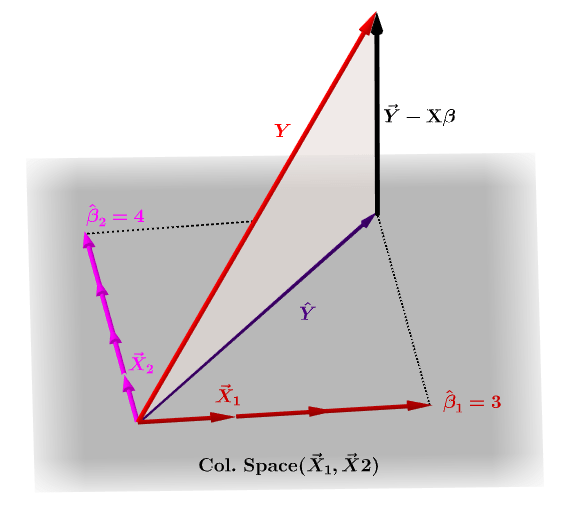
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Exercise 3 3 Consider The Hat Matrix H X X X Xt Chegg Com

The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science
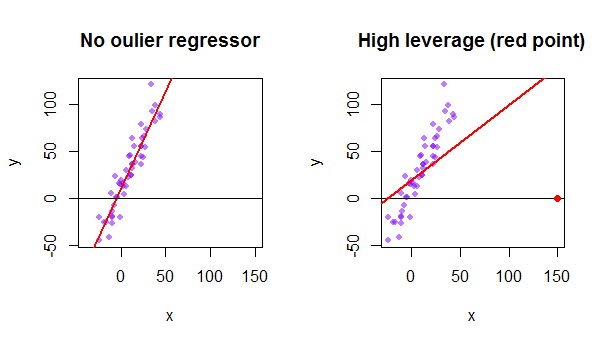
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Proof That The Trace Of Mx Is P Youtube

Hat Matrix An Overview Sciencedirect Topics

Hat Matrix Freakonometrics
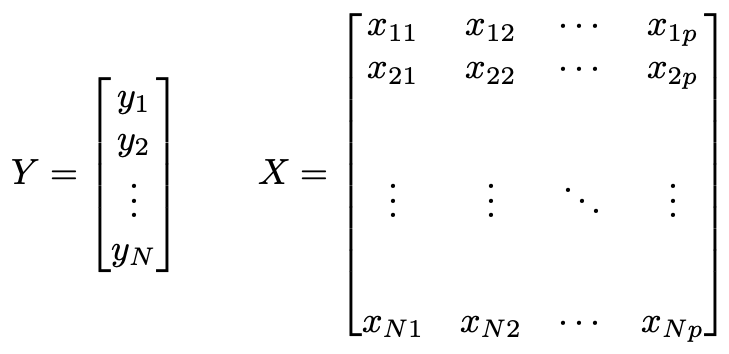
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science

Gate Ese Trace And Transpose Of A Matrix Offered By Unacademy

Hat Matrix An Overview Sciencedirect Topics

Hat Matrix An Overview Sciencedirect Topics

Gate Ese Matrix 8 Trace Transpose And Conjugate Of Matrix Offered By Unacademy
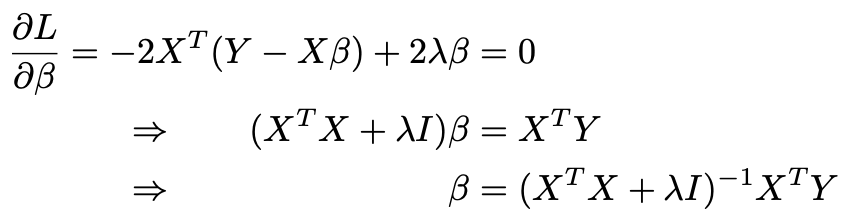
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science

