Hat Matrix Transpose
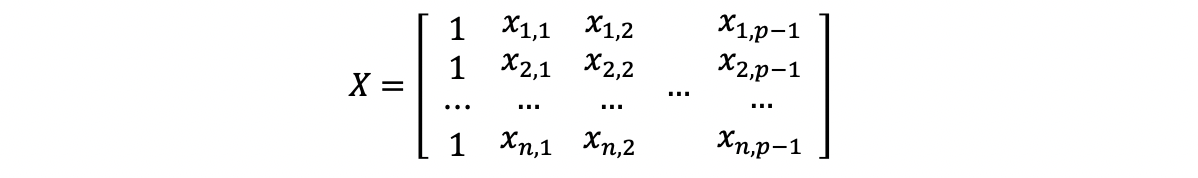
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

How Is It The Hat Matrix Spans The Column Space Of X Really Nice Youtube

Transpose Of A Matrix Video Khan Academy

Exercise 4 2 Class 12 Introduction Maths Solutions Exercise Class
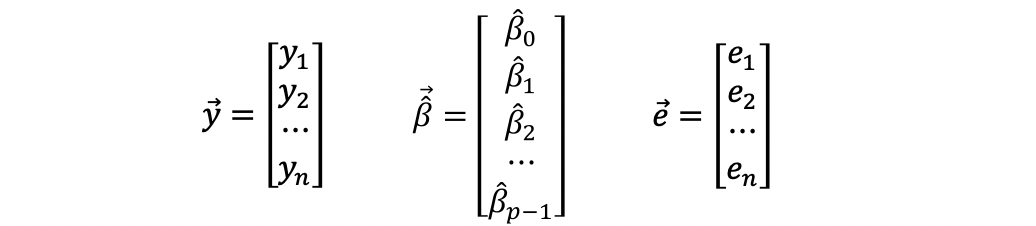
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium
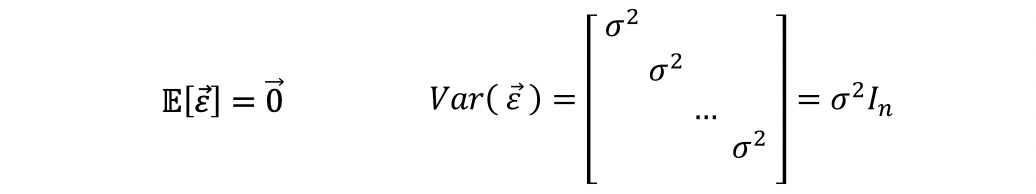
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

A new matrix is obtained the following way.
Hat matrix transpose. Dimension also changes to the opposite. For a given model with independent variables and a dependent variable the hat matrix is the. Along the way I present the proo.
Matrix transposes and symmetric matrices are linked in fact the definition of a symmetric matrix is that a symmetric matrix As transpose gives back the same matrix A. Write the elements of the rows as columns and write the elements of a column as rows. Viewed 2k times 5 2 begingroup large hat y Xhatbeta tag 1 seems to be the most commonly encountered expression of the ordinary least square projection.
The conjugate transpose of a matrix A is denote A. In matrix multiplication loop tiling is even more effective than taking the transpose but thats much more complicated. This is because for any invertible matrix X X T 1 X 1 T ie the operations of taking inverses and transposes commute.
In first case we are talking about two random variables X and Y. Zeile der Matrix A wird die 1. Each i j element of the new matrix gets the value of the j i element of the original one.
Matrix multiplication is O n3 and the transpose is O n2 so taking the transpose should have a negligible effect on the computation time for large n. For real matrices this concept coincides with the transpose for matrices over the complex field the conjugate is usually what you want anyway. 1 Hat Matrix for MLR The hat matrix in regression is just another name for the projection matrix.
To find the transpose of a matrix the rows of the matrix are written as the new columns of the transposed matrix. This is a continuation of my linear algebra series tied with the 1806 MIT OCW Gilbert Strang course on introductory linear algebra. We know that A-BT AT - BT.

Hat Y X T Hat Beta Matrix Dimension For Linear Regression Coefficients Beta Mathematics Stack Exchange
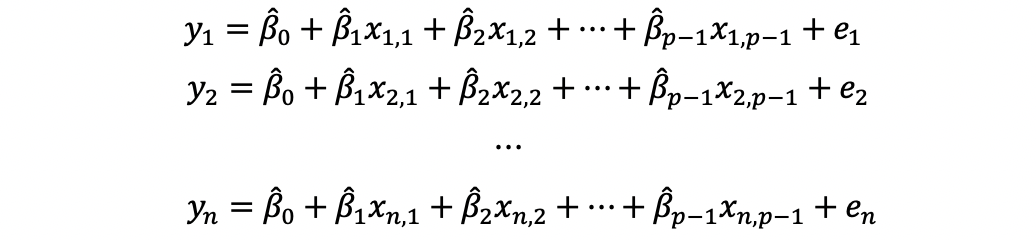
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

Mathematical Symbols Partial Derivative Symbols Glossary

Hat Matrix An Overview Sciencedirect Topics

What S The Use Of Matrices For Regression Analysis Youtube

Diode Dynamics Worklight Ss3 Sport Type B Kit White Sae Driving Led Fog Lights Diode Lexus Ct200h
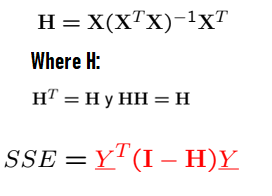
I Am Calculating The Sse In A Matrix Way In Python It Is Not Giving Me The Expected Value And The Hat Matrix H Is Not Symmetric And Idempotent Stack Overflow

Linear Regression Model In Matrix Form Studocu

How To Prove A Matrix Is Symmetric Youtube

Hat Matrix An Overview Sciencedirect Topics

Solved 2 Consider The Linear Model Y X B E Where E N Chegg Com

Program To Find The Sum Of Each Row And Each Column Of A Matrix Geeksforgeeks
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium

